At my new workplace at university I’m currently porting an advanced terrain rendering engine from DirectX to OpenGL. One of the performance optimizations the engine uses is that it draws the terrain tiles right from the index buffer without using a vertex buffer at all - that is it packs the vertex position into the 32-bit index and unpacks it in the vertex shader.
Why is this faster than rendering using a vertex buffer and no index buffer?
When using an index buffer the graphics card can make use of a cache of already transformed (vertex-shaded) vertices and when an index is reused, it can use the cached result instead of running the vertex shader again. Of course, this only works if there exists a certain temporal locality, but that is given. If no index buffer is used, the vertex cache won’t be used, because the implicit index is different for each vertex.
Since I need to port the engine from DirectX to OpenGL, I did some research to see if it is possible to do the same in OpenGL. It’s not really possible but you can achieve something quite similar in OpenGL 3.0.
Using the Input-Assembler Stage without Buffers (OpenGL)
This is meant as OpenGL analogon for Using the Input-Assembler Stage without Buffers (Direct3D 10).
I think the title is self-explanatory but for greater clarity let me
rephrase it: The aim is to render something without using vertex or
index buffers, that is (in OpenGL speak) using neither vertex data nor
an elements array to render something. Instead the automatically
supplied gl_VertexID attribute (vertexId in
DirectX) is used to determine the vertex the shader is currently
processing.
The example in MSDN simply draws a triangle using
vertexId:
VSOut VSmain(VSIn input)
{
VSOut output;
if (input.vertexId == 0)
output.pos = float4(0.0, 0.5, 0.5, 1.0);
else if (input.vertexId == 2)
output.pos = float4(0.5, -0.5, 0.5, 1.0);
else if (input.vertexId == 1)
output.pos = float4(-0.5, -0.5, 0.5, 1.0);
output.color = clamp(output.pos, 0, 1);
return output;
}If you want to do the same thing in OpenGL, you have at least two problems:
OpenGL uses
glVertex\*as end marker for the specification of a single vertex and the array rendering commands (glDrawArrays,glDrawElements, etc.) all require an enabled vertex array.gl_VertexIDis only supplied if:- the vertex comes from a vertex array command that specifies a complete primitive (e.g. DrawArrays, DrawElements)
- all enabled vertex arrays have non-zero buffer object bindings, and
- the vertex does not come from a display list, even if the display list was compiled using DrawArrays / DrawElements with data sourced from buffer objects.
(from GL_EXT_gpu_shader_4)
There is no way around these requirements, but what you can do is to create dummy vertex buffer with one element, bind it as vertex array and simply draw as many vertices as you want. If you don’t access gl_Vertex there is no way that uninitialized data can affect the shader and although behavior is generally undefined in OpenGL, if you render beyond the vertex buffer size, it has worked so far that I’ve test this on.
You can download the source code here.
Packing Vertex Positions into the Elements Array
The next step is to start packing and unpacking data in the
gl_VertexID. For this, an integer type and bit operations
(shifting and masking at least) are required in the vertex shader, so it
requires GLSL 1.30 at least.
The code is quite short from my proof of concept project, so I’m pasting the shader here:
#version 130
#extension GL_EXT_gpu_shader4 : enable
out vec4 color;
vec3 unpackVertex(int index) {
return vec3( index & 0xFF, (index >> 8 ) & 0xFF, (index >> 16) & 0xFF ) * (2 / 255.0) - vec3(1.0);
}
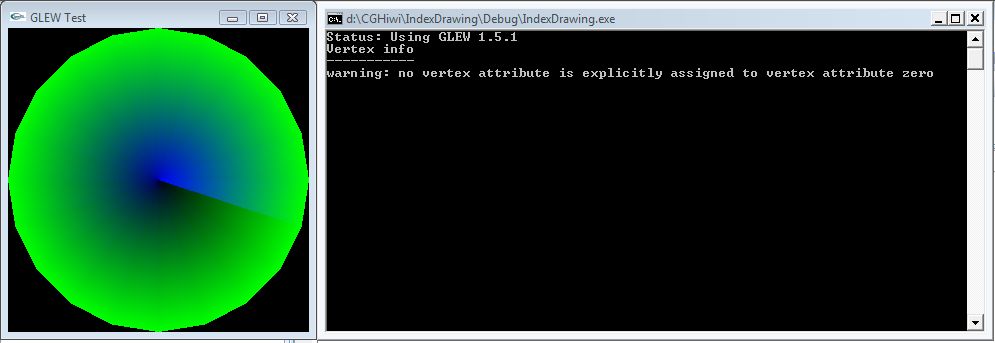
void main()
{
vec3 unpackedData = unpackVertex( gl_VertexID );
gl_Position = vec4( unpackedData, 1.0 );
color = vec4( (unpackedData + 1.0) / 2.0, 1.0 );
}In main.cpp the equivalent can be found for setting up the elements array:
#define packFloat(v) (int(((v) + 1.0) / 2 * 255) & 255)
#define packVertex(x,y,z) (packFloat( x ) + (packFloat( y ) << 8 ) + (packFloat( z ) << 16))
void display(void) {
[...]
unsigned indices[] = {
packVertex( 0.0, 0.0, -1.0 ), packVertex( 1.0, 0.0, -1.0 ), packVertex( 1.0, 1.0, -1.0 ),
packVertex( 0.0, 0.0, -1.0 ), packVertex( -1.0, 0.0, -1.0 ), packVertex( -1.0, -1.0, -1.0 )
};
glDrawElements( GL_TRIANGLES, sizeof( indices ) / sizeof( *indices ), GL_UNSIGNED_INT, indices );
[...]
}For the code to actually make sense I should initialize an index buffer/elements array buffer in OpenGL and upload the indices into it but this was just for testing.
You can download the source code here.
Note:
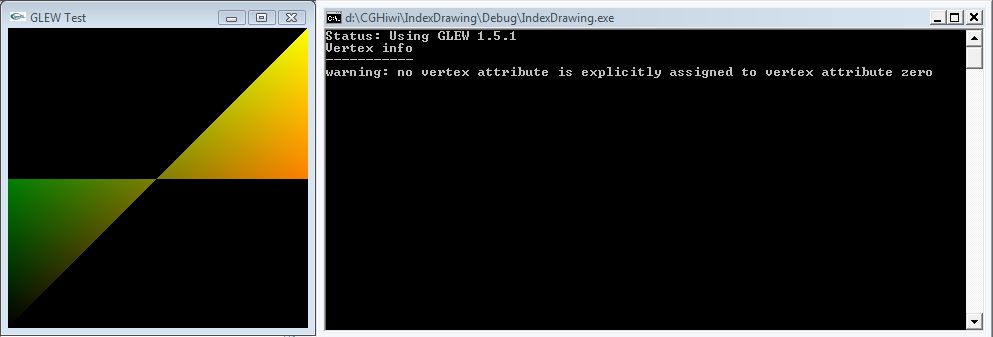
It has been brought to my attention (thanks Yagero), that on NVIDIA cards the driver currently reduces the element array data size from int to short, which causes the third byte (ie z values in this packing scheme) to always be 0.
A fix is to use an element array buffer (index buffer) which prevents the driver from messing with the data size.
You can download the adapted source code here. To show that it works, I have swapped the x and z component in the packing scheme.